
Web Scraping in Python using Beautiful Soup


4 min read
What is Beautiful Soup and what are it's features
If you prefer watching a video:
Beautiful Soup is a great Python library that allows you to parse the HTML content and extract the specific data that you need from the page source.
Here are some of the main features that make Beautiful Soup is used for Web scraping data:
Allows you to seperate the data points you need from large HTML content
Easy to get started with.
Can be used with Requests or Selenium library to extract data.
The features are endless, so now let's get started with using this Powerful Library with Python.
Installation
Before we install Beautiful Soup and other libraries, make sure you have Python downloaded and Installed on your PC. You can download it from here: python.org
Now, to install the Beautiful Soup library, run the below command in cmd:
pip install requests html5lib beautifulsoup4
This will also install another library called requests and html5lib, which will allow us to get HTML content from a page so that we can later use Beautiful Soup with Python.
Quickstart
Now let's Extract some HTML content from a webpage so that we can later use Beautful soup to parse it.
Code for extracting HTML content from the webpage: https://books.toscrape.com/
import requests
URL = "https://books.toscrape.com/"
r = requests.get(URL)
print(r.content)
Now that it is extracted, we can parse it using Beautiful soup
import requests
from bs4 import BeautifulSoup
URL = "https://books.toscrape.com/"
r = requests.get(URL)
page_source = (r.content)
soup = BeautifulSoup(page_source, 'html.parser')
# Extracting all the links
links = soup.find_all('a')
print("All Links:", links)
Scraping Data
Now to extract Book names from the html content of the page:
# Find all h3 elements and extract their text content
h3_elements = soup.find_all('h3')
for h3_element in h3_elements:
# Extract the text content of the h3 element
text_content = h3_element.get_text(strip=True)
print(text_content)
This will print the below data in CMD:
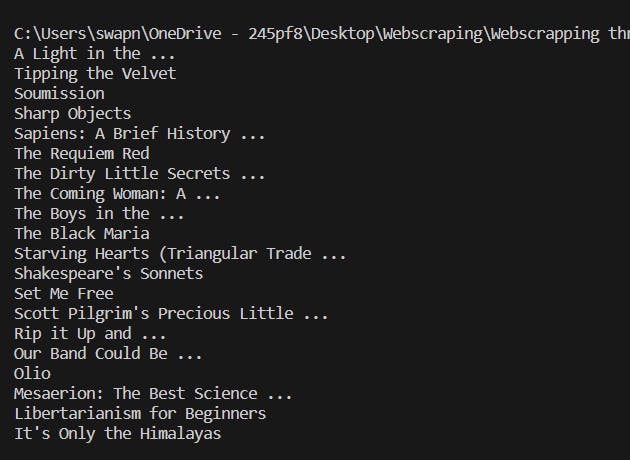
Similarly to get all the links from the h3 elements:
# Find all h3 elements
h3_elements = soup.find_all('h3')
# Extract links from each h3 element
for h3_element in h3_elements:
link_element = h3_element.find('a')
link = link_element.get('href') if link_element else None
print(link)
Finally, we can save the data we collected in a CSV file.
Here's the code to save both the Title of the book and their Links in a CSV file:
import requests
from bs4 import BeautifulSoup
import csv
URL = "https://books.toscrape.com/"
r = requests.get(URL)
page_source = r.content
soup = BeautifulSoup(page_source, 'html.parser')
h3_elements = soup.find_all('h3')
# Create a list to store data
data = []
for h3_element in h3_elements:
text_content = h3_element.get_text(strip=True)
link_element = h3_element.find('a')
link = link_element.get('href') if link_element else None
# Append data to the list
data.append({'Title': text_content, 'Link': link})
print(text_content, link)
# Save data to a CSV file
csv_filename = "Scraped_books.csv"
fields = ['Title', 'Link']
with open(csv_filename, 'w', newline='', encoding='utf-8') as csv_file:
csv_writer = csv.DictWriter(csv_file, fieldnames=fields)
# Write the header
csv_writer.writeheader()
# Write the data
csv_writer.writerows(data)
print(f"Data saved to {csv_filename}")
After running the above code, you should get a CSV file named "Scraped_books.csv" in the folder which looks like:
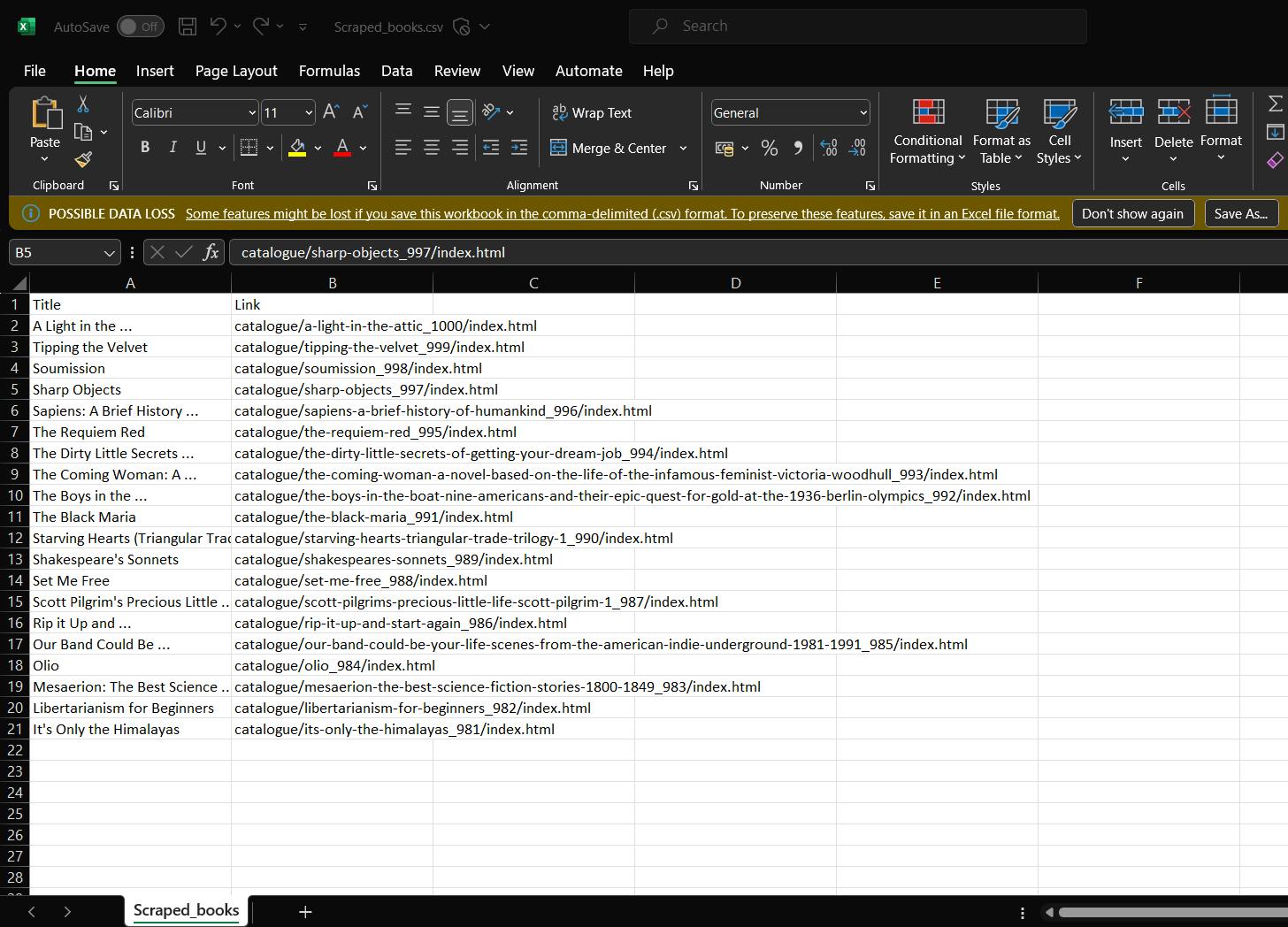
The possibilities are endless with Web scraping. Web scraping is legal, but make sure you scrape the data Responsibly and do not harm the website in any way while scraping, and respect the copyright rules.
Hope you found this article useful in starting your scraping journey. Happy Scraping!
Next Steps to take to become a Data Extraction Expert
The next steps would be to learn more complex Technologies used in Web scraping.
Before you do that, I will suggest making a list of your 2-3 favorite websites and try scraping some simple data from them from the things we learned.
Don't spend more than 1-2 days on each of them and if you fail, research on how you can solve them.
For the websites you fail, most probably, you will need a stronger Technology to scrape the data.
You can learn more about those from here: