
Cruisemapper Cruises Scraper
The Cruisemapper Cruises Scraper extracts detailed cruise data, including ship names, itineraries, departure dates, prices, and more. Receive structured data in JSON, CSV, or Excel formats for travel planning, market research, or integration into applications.
The Cruisemapper Cruises Scraper is a powerful tool designed to extract detailed cruise data from Cruisemapper. It collects essential information such as ship names, itineraries, departure dates, prices, and more, delivering structured output in JSON, CSV, or Excel formats. Ideal for travel planning, market research, or integration into applications.
Features
- Ship Details: Extracts ship names, cruise titles, departure dates, and cruise line operators.
- Pricing Information: Retrieves cruise pricing (where available).
- Itinerary Stops: Captures detailed stop data, including dates and descriptions for multiple destinations.
- Flexible Data Output: Provides results in JSON, CSV, or Excel for easy integration.
- User-Friendly Input: Specify date ranges and number of pages to scrape.
Input Schema
The actor accepts the following input parameters:
| Parameter | Type | Description | Required | Default |
|---|---|---|---|---|
start_date | string | The start date for the cruises to scrape (format: YYYY-MM-DD). Must match the regex. | Yes | 2025-01-01 |
end_date | string | The end date for the cruises to scrape (format: YYYY-MM-DD). Must match the regex. | Yes | 2025-01-31 |
cruise_length | string | Filter by cruise length. | No | 0 |
ship_name | string | Filter by ship name. | No | |
cruise_line | string | Filter by cruise line. | No | |
departure_port | string | Filter by departure port. | No | |
destination | string | Filter by destination. | No | 0 |
ship_type | string | Filter by ship type. | No | 0 |
port_of_call | string | Preferable port of call / country. | No | |
max_number_of_pages | integer | Maximum number of pages to scrape. Use -1 to scrape all available pages. | No | -1 |
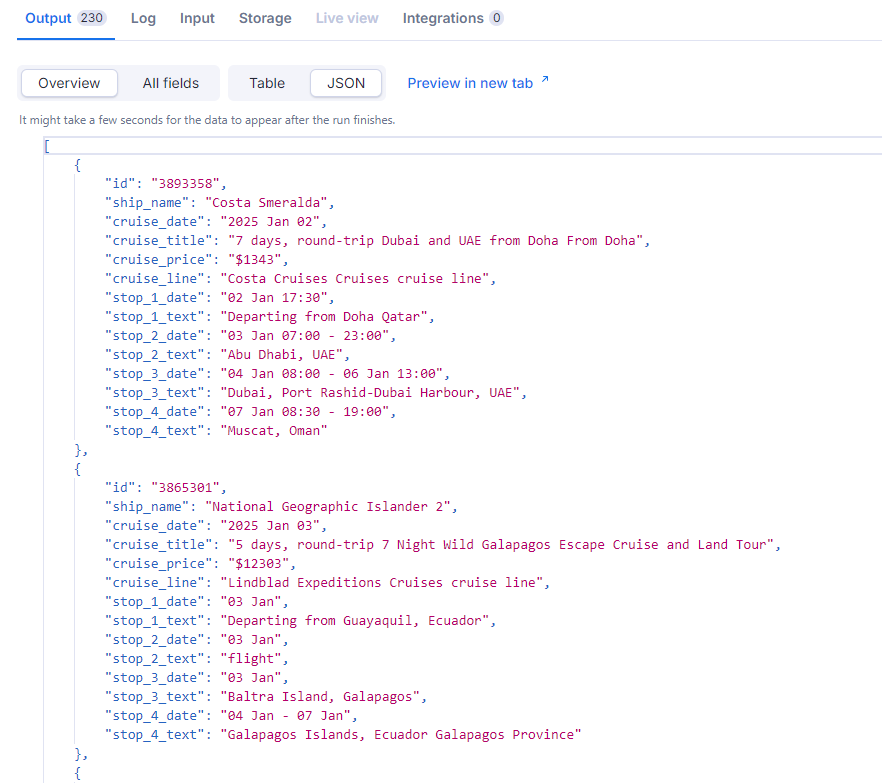
Example Output
Below is an example of the structured data produced by the actor:
1{ 2 "id": "3104881", 3 "ship_name": "MS Deutschland-World Odyssey", 4 "cruise_date": "2023 Sep 09", 5 "cruise_title": "104 days, one-way from Amsterdam to Tokyo", 6 "cruise_price": "", 7 "cruise_line": "Phoenix Reisen Cruises cruise line", 8 "stop_1_date": "09 Sep 20:00", 9 "stop_1_text": "Departing from Amsterdam, Netherlands North Holland", 10 "stop_2_date": "17 Sep 08:00 - 13 Apr 20:00", 11 "stop_2_text": "Barcelona, Spain", 12 "stop_3_date": "27 Sep 08:00 - 30 Sep 20:00", 13 "stop_3_text": "Piraeus-Athens, Greece", 14 "stop_4_date": "05 Oct 08:00 - 08 Oct 20:00", 15 "stop_4_text": "Aqaba, Petra, Jordan" 16}
How to Use
-
Set Up the Actor:
- Install the actor from the Apify platform.
-
Provide Input Parameters:
start_date: The start date for the cruises inDD-MMM-YYYYformat (e.g.,01-Jan-2016).end_date: The end date for the cruises inDD-MMM-YYYYformat (e.g.,24-Nov-2024).max_number_of_pages: The maximum number of pages to scrape (-1for all pages).
-
Run the Actor:
- Execute the actor on the Apify platform.
-
View Results:
- Access the structured data in JSON, CSV, or Excel formats via the dataset.
Use Cases
- Travel Planning: Gather detailed cruise itineraries and schedules for personal or agency use.
- Market Research: Analyze trends in cruise pricing, popular destinations, and cruise line offerings.
- Data Integration: Seamlessly integrate cruise data into travel applications or analytics systems.
- Competitor Analysis: Compare offerings across different cruise lines for strategic planning.
- Content Creation: Generate accurate, structured data for blogs, articles, or travel guides.
Support
For assistance or feature requests, you can:
- Open an issue on the Apify community forums or the GitHub repository.
- Contact Apify support through the platform’s support portal.
- Refer to the Apify documentation for general troubleshooting tips.
Related Actors
Explore More Actors
✨ Looking for something else? Check out more actors on Apify that can help with your web automation and data extraction needs. Discover a wide range of tools tailored for different scenarios at 🌐 Explore Vulnv's Actors on Apify.
📧 For inquiries or support, feel free to reach out to us at apify@vulnv.com.
Frequently Asked Questions
Is it legal to scrape job listings or public data?
Yes, if you're scraping publicly available data for personal or internal use. Always review Websute's Terms of Service before large-scale use or redistribution.
Do I need to code to use this scraper?
No. This is a no-code tool — just enter a job title, location, and run the scraper directly from your dashboard or Apify actor page.
What data does it extract?
It extracts job titles, companies, salaries (if available), descriptions, locations, and post dates. You can export all of it to Excel or JSON.
Can I scrape multiple pages or filter by location?
Yes, you can scrape multiple pages and refine by job title, location, keyword, or more depending on the input settings you use.
How do I get started?
You can use the Try Now button on this page to go to the scraper. You’ll be guided to input a search term and get structured results. No setup needed!