
🔥 Easy RedNote (XiaoHongShu) Scraper
Extract trending posts and user data from RedNote (XiaoHongShu). Automatically scrape posts across categories like 🏠Homefeed, 👗Fashion, 🍜Food, 💄Cosmetics, 🎬Movie & TV, 💼Career, ❤️Love, 🛠️Household, 🎮Gaming, ✈️Travel, and 💪Fitness.
✨ Features
- 🎯 Smart Targeting: Choose from 11 different content categories
- ⚡ Lightning Fast: Optimized scrolling and data extraction
- 🛡️ Anti-Bot Protection: Advanced mechanisms to avoid detection
- 🤖 Intelligent Scrolling: Dynamic content loading with smart wait times
- 🔄 Smart Recovery: Auto-resumes from failures and handles network issues
🎯 Use Cases
- 📱 Social Media Marketing: Track trending content and influencers
- 🔍 Market Research: Analyze consumer preferences and trends
- 🎨 Content Creation: Get inspiration from top-performing posts
- 👥 Influencer Discovery: Find and analyze popular creators
- 📊 Competitor Analysis: Monitor competitor content and engagement
📋 What Data You Get
| Field | Description |
|---|---|
| post_title | Title of the post |
| post_likes | Number of likes on the post |
| post_url | Direct link to the post |
| author_name | Username of the post creator |
| author_id | Unique identifier of the author |
| author_avatar | URL of author's profile picture |
| author_profile_url | Link to author's profile |
🚀 How do I use RedNote (XiaoHongShu) Scraper to scrape website data?
-
Choose Category: Select any category:
- 🏠 Homefeed
- 👗 Fashion
- 🍜 Food
- 💄 Cosmetics
- 🎬 Movie & TV
- 💼 Career
- ❤️ Love
- 🛠️ Household
- 🎮 Gaming
- ✈️ Travel
- 💪 Fitness
-
Set Volume: Choose how many posts to collect
-
Start Scraping: Click Run and watch the data flow
-
Download: Get your data in JSON, CSV, or Excel
📊 Example Input
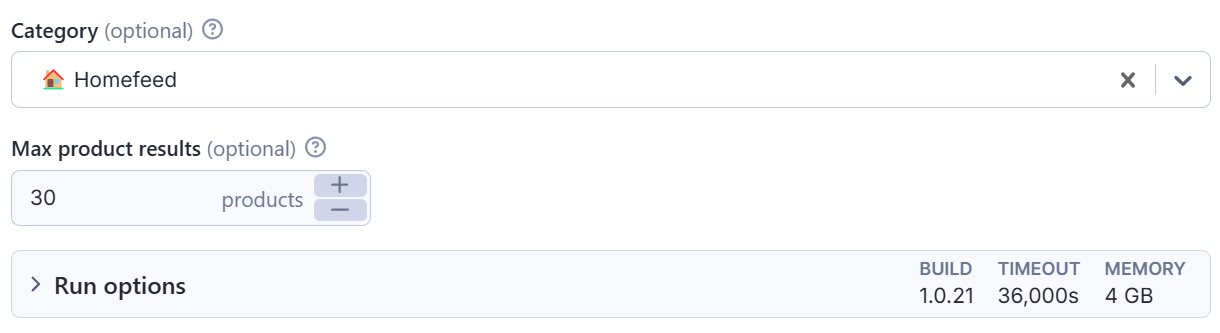
Json input
1{ 2 "category": "homefeed", // Available categories: homefeed, fashion, food, cosmetics, movie_tv, career, love, household, gaming, travel, fitness 3 "max_results": 100 4}
📈 Sample Output
You can download the dataset extracted by RedNote (XiaoHongShu) Scraper in various formats such as JSON, HTML, CSV, or Excel.
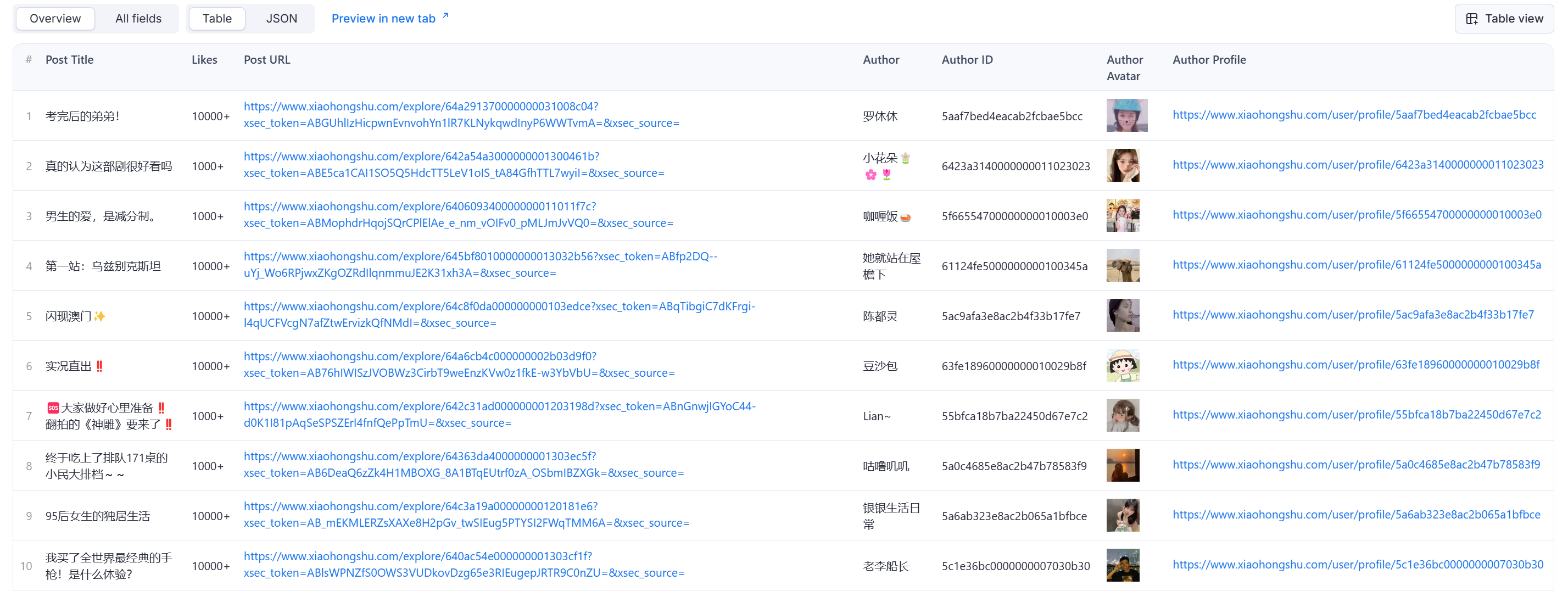
Json output
1{ 2 "post_title": "考完后的弟弟!", 3 "post_likes": "10000+", 4 "post_url": "https://www.xiaohongshu.com/explore/64a291370000000031008c04?xsec_token=ABGUhlIzHicpwnEvnvohYn1lR7KLNykqwdInyP6WWTvmA=&xsec_source=", 5 "author_name": "罗休休", 6 "author_id": "5aaf7bed4eacab2fcbae5bcc", 7 "author_avatar": "https://sns-avatar-qc.xhscdn.com/avatar/60606ae386182e403e327dfb.jpg?imageView2/2/w/60/format/webp|imageMogr2/strip", 8 "author_profile_url": "https://www.xiaohongshu.com/user/profile/5aaf7bed4eacab2fcbae5bcc" 9}
❓ FAQ
Is it legal to scrape XiaoHongShu?
Our scraper only collects publicly available data while respecting the site's terms. For large-scale scraping, review XiaoHongShu's terms of service.
Need Help?
- 🐛 Found a bug? Create an issue.
- 💡 Need customization? Contact us for tailored solutions
Frequently Asked Questions
Is it legal to scrape job listings or public data?
Yes, if you're scraping publicly available data for personal or internal use. Always review Websute's Terms of Service before large-scale use or redistribution.
Do I need to code to use this scraper?
No. This is a no-code tool — just enter a job title, location, and run the scraper directly from your dashboard or Apify actor page.
What data does it extract?
It extracts job titles, companies, salaries (if available), descriptions, locations, and post dates. You can export all of it to Excel or JSON.
Can I scrape multiple pages or filter by location?
Yes, you can scrape multiple pages and refine by job title, location, keyword, or more depending on the input settings you use.
How do I get started?
You can use the Try Now button on this page to go to the scraper. You’ll be guided to input a search term and get structured results. No setup needed!