
Twitter 🐦 Jobs Scraper
Scrape Twitter Jobs
Welcome to Twitter Jobs Scraper


About Twitter.com
Twitter is an online social media and social networking service owned and operated by American company X Corp., the legal successor of Twitter, Inc. Twitter users outside the United States are legally served by the Ireland-based Twitter International Unlimited Company, which makes these users subject to Irish and European Union data protection laws[9][10]
About This Actor
⭐ Scrape Jobs opportunities from https://twitter.com/jobs
For complete scraping other Twitter Resources please use 🐦 Twitter X-Plorer Actor.
HTTP Cookies
Some function need auth_token to work properly (required sign-in to Twitter.com). When you receive log error something like below, then probably you need to supply parameters with auth_token value.
1❌ Authorization: Denied by access control: unspecified reason 2❌ HTTP error 404: Not Found
Important Notes :
- This is NOT your APIFY Token, instead a value from your browser cookie, named auth_token.
- Use this only if necessary, as it have risk your account getting blocked by @elonmusk.
- Your cookies is your SECRET. Please don't share it with someone else.
- The auth_token value will always valid until you logged out from Twitter.com
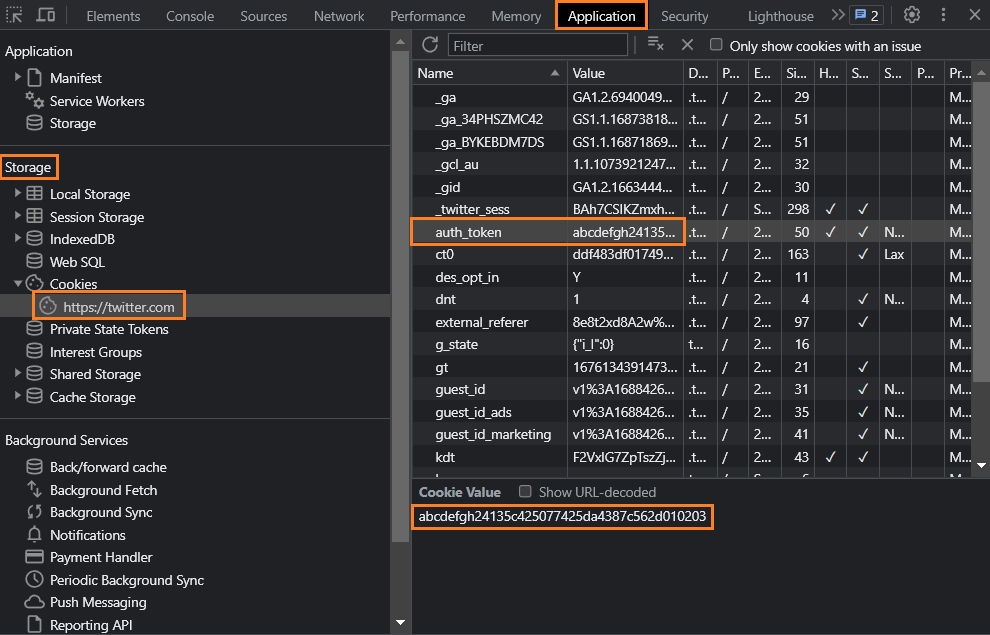
To get auth_token cookie value :
- Login to Twitter.com
- Open Chrome Developer Tools (Ctrl + Shift + I)
- Open Application Tab
- On left panel, go to: Storage -> Cookies -> https://twitter.com
- Find cookie named auth_token (40 characters string value).
- Copy & Paste Here :
1{ 2 "query": "python software engineer", 3 "token": "YOUR_TWITTER_AUTH_TOKEN" 4}
Frequently Asked Questions
Is it legal to scrape job listings or public data?
Yes, if you're scraping publicly available data for personal or internal use. Always review Websute's Terms of Service before large-scale use or redistribution.
Do I need to code to use this scraper?
No. This is a no-code tool — just enter a job title, location, and run the scraper directly from your dashboard or Apify actor page.
What data does it extract?
It extracts job titles, companies, salaries (if available), descriptions, locations, and post dates. You can export all of it to Excel or JSON.
Can I scrape multiple pages or filter by location?
Yes, you can scrape multiple pages and refine by job title, location, keyword, or more depending on the input settings you use.
How do I get started?
You can use the Try Now button on this page to go to the scraper. You’ll be guided to input a search term and get structured results. No setup needed!